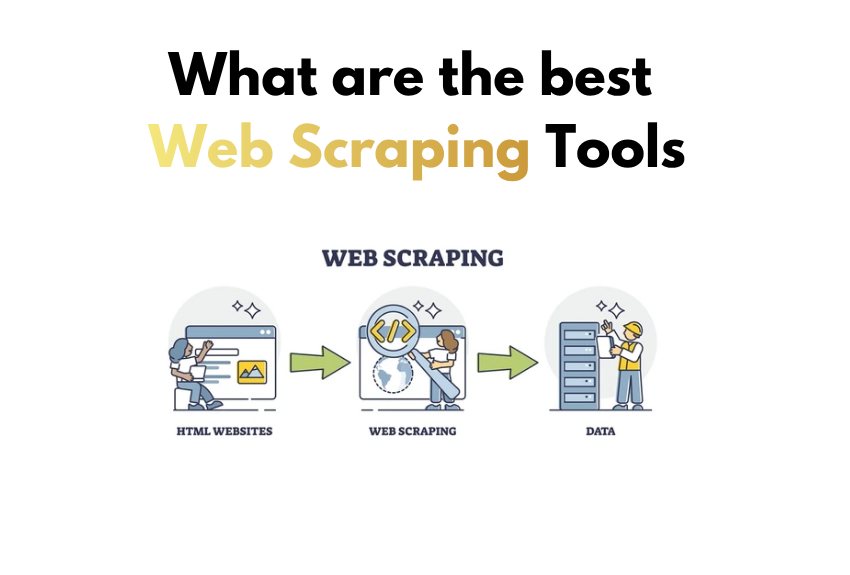
Web scraping tools are essential for quickly and efficiently gathering data from the internet, transforming raw web data into actionable insights for businesses and researchers.
They are invaluable for businesses tracking competitors, researchers compiling data for studies, and developers integrating information into their applications. With so many options available, selecting the right tool can feel daunting.
In this comprehensive guide, we'll explore the top web scraping tools on the market in 2025, discussing what each one does, its pros and cons, and how it can fit into your data collection workflow.
01 What is Web Scraping?
Web scraping is a technique used to extract data from websites. It involves utilizing tools that automatically collect information from the web. Depending on the type of data you need, various tools are designed for specific tasks to make the process more efficient.
"Web scraping empowers businesses to make data-driven decisions by transforming raw web data into actionable insights."
How Web Scraping Works:
Sending Requests
The scraper sends a request to a website's server to access the page content.
Parsing Data
The scraper reads and interprets the HTML/XML data returned by the server.
Extracting Information
Relevant data is extracted and organized into structured formats like CSV or JSON.
Storing Results
Data is saved in databases, spreadsheets, or other storage systems for analysis.
Job Market Analysis
Collecting job listings from various websites for market research and opportunity tracking.
Financial Data
Monitoring stock prices, commodity values, and financial news for investment decisions.
Search Engines
Keeping search results updated with latest content from across the web.
E-commerce
Price comparison, product tracking, and competitive analysis for retail businesses.
02 Key Benefits of Web Scraping Tools
Before exploring specific tools, understanding the core benefits helps in selecting the right solution for your needs. Modern web scraping tools offer significant advantages over manual data collection methods.
Scalability
Handle large volumes of data across multiple websites simultaneously, suitable for businesses of all sizes.
Efficiency
Automates time-consuming manual data collection, processing thousands of pages in minutes instead of days.
Accuracy
Eliminates human error in data entry, ensuring consistent and reliable data extraction.
Additional Advantages:
Cost-Effective
Reduces labor costs associated with manual data entry and research.
Real-time Data
Access to current information for timely decision-making and market analysis.
Automated Updates
Schedule regular data collection to keep information current without manual intervention.
Strategic Value
Beyond technical advantages, web scraping provides strategic business value through competitive intelligence, market research, and data-driven decision making that can significantly impact business growth and market positioning.
03 Scrapy: The Python Powerhouse
Scrapy is a Python-based framework designed for larger, more complex web scraping projects. It's a comprehensive solution capable of handling intricate tasks and large-scale data extraction.
Python-Based
Built on Python with extensive library support and community resources.
High Performance
Asynchronous processing for fast scraping of large volumes of data.
Framework Structure
Complete framework with built-in features for complex scraping workflows.
Best Use Cases for Scrapy:
01
Large-Scale Projects
Ideal for scraping thousands of pages with complex data structures.
02
Complex Data Extraction
Handles websites with JavaScript rendering, login requirements, and pagination.
03
Production Environments
Suitable for ongoing data collection pipelines and automated systems.
Learning Curve
Requires Python programming knowledge and understanding of web scraping concepts.
Development Time
Initial setup and configuration takes longer than no-code alternatives.
Maintenance Required
Needs regular updates to handle website changes and structure modifications.
04 Beautiful Soup: The Beginner's Choice
Beautiful Soup is an excellent Python library for beginners and intermediate users, widely used for parsing HTML and XML documents. It simplifies the process of extracting data from web pages.
Beginner
Easy to Learn
Simple syntax and extensive documentation make it ideal for beginners.
Flexible
Integration Friendly
Works well with requests, urllib, and other Python libraries.
Lightweight
Minimal Setup
Quick installation and minimal configuration required to start scraping.
When to Choose Beautiful Soup:
Learning Projects
Perfect for educational purposes and understanding web scraping fundamentals.
Small to Medium Tasks
Ideal for scraping data from a few hundred pages with simple structures.
HTML/XML Parsing
Excellent for extracting specific elements from well-structured documents.
Quick Prototypes
Fast development of scraping scripts for testing and validation.
Beautiful Soup provides the perfect balance between simplicity and power for developers who need to extract data quickly without the complexity of a full framework like Scrapy.
05 ParseHub: No-Code Visual Scraping
ParseHub is a visual data extraction tool designed to manage complex web scraping tasks without requiring programming skills. Perfect for business users and non-technical teams.
Point-and-Click Interface
Select data elements visually without writing any code or scripts.
Complex Navigation
Handle multi-step workflows, pagination, and login-required pages.
Cloud-Based
Run scrapers on ParseHub's servers with scheduling and automation features.
ParseHub Features:
Scheduled Scraping
Automate data collection at regular intervals without manual intervention.
Multiple Export Formats
Export data to JSON, Excel, CSV, or integrate via API to other systems.
IP Rotation
Avoid IP blocking with automatic IP rotation during large-scale scraping.
JavaScript Rendering
Handle modern websites that rely heavily on JavaScript for content.
ParseHub offers both free and paid plans, with the free version suitable for small projects and the paid plans providing advanced features for business use cases including API access and larger data limits.
06 WebHarvy: Desktop Scraping Simplified
WebHarvy is an intuitive desktop-based web scraping tool that makes data collection easy with a simple point-and-click interface, requiring no programming skills.
Desktop Application
Runs locally on your computer with no cloud dependencies or subscription fees.
Automatic Pattern Detection
Intelligently identifies data patterns on web pages for easy extraction.
Image & File Download
Extract not just text but also images, PDFs, and other file types.
Key Advantages:
One-Time Purchase
No recurring subscription fees - pay once and use indefinitely.
Team-Friendly
Share scraping configurations with team members for collaborative projects.
Built-in Scheduler
Schedule scraping tasks to run automatically at specified times.
Ideal User Profile
WebHarvy is perfect for business analysts, researchers, and marketers who need to extract data regularly but don't have programming skills. Its one-time purchase model makes it cost-effective for long-term use.
07 Import.io: Enterprise-Grade Data Platform
Import.io is a powerful web data integration platform that provides both no-code and API options for data extraction, designed for enterprise use cases and large-scale data operations.
Enterprise Focus
Built for business teams with collaboration features and enterprise security.
API Integration
Robust API for integrating scraped data directly into business applications.
Data Transformation
Built-in tools for cleaning, structuring, and transforming extracted data.
Export Capabilities:
01
CSV & Excel
Direct export to spreadsheet formats for immediate analysis.
02
JSON & XML
Structured data formats for developers and system integration.
03
Cloud Storage
Direct upload to Google Sheets, Dropbox, and other cloud services.
Import.io stands out for businesses that need reliable, scalable web data extraction integrated into their existing workflows, with enterprise-grade support and compliance features.
08 Octoparse: Hybrid Approach
Octoparse offers a user-friendly web scraping tool with both visual interface and advanced scripting capabilities, making it suitable for both beginners and technical users.
Versatile
Dual Interface
Visual point-and-click for beginners, advanced mode for developers.
Cloud
Cloud Execution
Run scraping tasks in the cloud with 24/7 availability and monitoring.
Powerful
Dynamic Websites
Excellent handling of JavaScript-heavy and dynamically loaded content.
Octoparse Features:
Mobile App
Monitor and manage scraping tasks from your mobile device.
Workflow Templates
Pre-built templates for common scraping tasks to get started quickly.
Custom Functions
Add custom JavaScript functions for complex data processing.
Team Collaboration
Share projects and collaborate with team members on scraping tasks.
Octoparse offers a free version with basic features suitable for small projects, and paid plans with advanced features for business users. The visual interface makes it accessible while the advanced options provide power when needed.
09 Factors to Consider When Choosing
Selecting the right web scraping tool depends on your specific requirements, technical expertise, and project scope. Consider these key factors before making your decision.
Technical Expertise
Your team's programming skills determine whether to choose code-based or no-code solutions.
Project Scale
Number of pages, frequency of updates, and data volume requirements.
Budget Constraints
One-time purchase vs. subscription models, and total cost of ownership.
Best Practices for Successful Web Scraping:
Respect Website Terms
Always check and comply with the terms of service of websites you scrape.
Use Proxies
Implement proxy rotation to avoid IP blocking during large-scale scraping.
Error Handling
Build robust error handling to manage connection issues and site changes.
Regular Maintenance
Update scraping scripts regularly to handle website structure changes.
Data Cleaning
Implement data validation and cleaning processes for quality output.
Rate Limiting
Add delays between requests to avoid overwhelming target servers.
Ethical Considerations
Always scrape ethically by respecting robots.txt files, avoiding excessive server load, using data responsibly, and complying with copyright and privacy laws. Building good relationships with data sources often yields better long-term results.
Conclusion: Choosing Your Ideal Web Scraping Tool
Selecting the right web scraping tool significantly impacts your data collection efficiency and success. Each tool has its strengths and is suited for different use cases and user profiles.
For Developers
Scrapy and Beautiful Soup offer maximum flexibility and control for technical teams.
For Business Users
ParseHub, WebHarvy, and Import.io provide no-code solutions with enterprise features.
For Teams
Octoparse and Import.io offer collaboration features for shared projects.
For Scalability
Scrapy and cloud-based tools handle large volumes and complex requirements.
The best web scraping tool is the one that aligns with your technical capabilities, project requirements, and budget while providing reliable data extraction that supports your business objectives.
Whether you're tracking competitors, conducting market research, aggregating content, or building data-driven applications, the right web scraping tool can transform how you collect and utilize web data. Evaluate your needs carefully, consider starting with free trials or versions, and choose a tool that grows with your requirements.
Need Help with Web Scraping or Data Integration?
XV Digital Group specializes in custom web scraping solutions and data integration services. Whether you need help selecting the right tool, building custom scrapers, or integrating web data into your business applications, our team of experts can help you harness the power of web data efficiently and ethically.
Discuss Your Data Needs
Related Articles

